View PDF
Evaluation is the process of measuring how well a Conversational AI system performs its intended task. Historically, evaluation was a subjective “black box” process, but since the 1990s (starting with projects like the DARPA Communicator), it has evolved into a rigorous scientific field. This shift allowed for the systematic comparison of systems across different research laboratories and companies.
Evaluation is essential for three primary groups:
-
Developers: To debug, identify bottlenecks, and ensure the system performs as designed. For example, determining if a high error rate is caused by the speech recognizer or the natural language understanding unit.
-
Users: To ensure the system meets their needs—whether it understands their intent or, in non-task systems, whether it provides an enjoyable and engaging experience.
-
Researchers: To establish whether the aims of a study have been met, such as validating a new machine learning technique against baseline “State-of-the-Art” (SOTA) systems.
1. The Process of Evaluation: Environments and Methods
How we conduct a study significantly changes the results. There are two primary environments:
1.1 Laboratory Studies vs. “In the Wild”
-
Laboratory Studies: Conducted in a controlled environment with recruited participants.
-
Pros: Tightly controlled; ensures high within-test reliability; allows for extensive feedback collection.
-
Cons: The “Hawthorne Effect” (users act more patiently or formally when watched); laboratory users often produce a lower word error rate because they are in a quiet room rather than a noisy street.
-
-
Evaluations in the Wild: Real users interacting with a real system for a real purpose (e.g., the CMU “Let’s Go!” bus schedule system).
-
Pros: High validity; captures real-world environmental noise and higher “cognitive load” (users may be walking or distracted).
-
Cons: Hard to control variables; users give up quickly if the system fails, leading to higher “Abandonment Rates.”
-
1.2 User Simulators
Recruiting humans is expensive and slow. User Simulators are software agents designed to “act” like a human user to generate large amounts of training data for statistical models.
-
Agenda-Based Simulators: The simulator is given a “goal” (e.g., “Book a ticket for Batman at 7 PM”). It maintains an internal “agenda” of inform slots (data to give) and request slots (data to get).
-
Stochastic Simulators: Use probability (learned from real dialogue corpora) to decide the next move. While more “human-like,” it is often difficult to ensure they reproduce the full variety of real human behavior.
1.3 Crowdsourcing
Platforms like Amazon Mechanical Turk (AMT) allow researchers to hire hundreds of “Turkers” to evaluate dialogues. This is more efficient and cost-effective than laboratory recruitment and has become the standard for training open-domain AI models.
2. Evaluating Task-Oriented Dialogue Systems
These systems have a clear goal (e.g., hotel reservations). Evaluation focuses on Efficiency (how fast) and Effectiveness (did it work).
2.1 Quantitative Metrics (Objective)
These are retrieved from system logs or calculated by annotators:
-
Task Success: Often measured via the Kappa Coefficient, which accounts for the probability of the system getting the answer right by pure chance.
-
Dialogue Efficiency: Includes Dialogue Duration, Turn Count, and Time-to-task (how long before the user actually starts the task after hearing intros).
-
Commercial Metrics: * Containment Rate: Percentage of calls handled by the AI without needing a human agent.
- Correct Transfer Rate: How often the user is redirected to the right human department.
-
ASR Metrics: Word Error Rate (WER), calculated as
(S + D + I) / N(Substitutions, Deletions, Insertions divided by total words).
2.2 Sub-Component Evaluation (The Modular View)
If a system is modular, developers must solve the “Credit Assignment Problem”—deciding which specific component caused a dialogue to fail.
-
ASR (Speech): Accuracy of the transcription.
-
NLU (Understanding): Evaluated via Intent Classification (did it understand the user wanted a “flight”?) and Entity Extraction (did it catch “London”?).
-
DM (Manager): Measured by the Correction Rate—how many system turns were needed to fix a misunderstanding.
-
NLG (Generation): Evaluated for Informativeness (did it include all needed data?) and Naturalness (does it sound like a native speaker?).
-
TTS (Voice): Evaluated for Intelligibility and Likeability.
2.3 Qualitative Metrics (Subjective)
Users rate their experience on Likert Scales (e.g., 1 “Strongly Disagree” to 7 “Strongly Agree”).
-
SASSI (Subjective Assessment of Speech System Interfaces): A 34-item tool covering:
-
System Response Accuracy: “The system is accurate.”
-
Habitability: “I always knew what to say to the system.”
-
Annoyance: “The interaction is irritating/inflexible.”
-
3. Evaluating Open-Domain Dialogue Systems (Chatbots)
Open-domain systems (chatbots) lack a functional goal, so success is measured by the “quality” of the talk.
3.1 Exchange-Level Evaluation (Single Turn)
-
Machine Translation Metrics (BLEU/METEOR): These measure word overlap with a human reference.
- The “One-to-Many” Problem: In chat, there are thousands of valid responses. A bot might give a perfect answer that has zero word overlap with the reference, causing BLEU to give it a “failing” score incorrectly.
-
SSA (Sensibleness and Specificity Average):
-
Sensibleness: Does the response make sense in the current context?
-
Specificity: Is it specific? If a user says “I love pizza,” a response of “Ok” is sensible but not specific. A specific response would be “What’s your favorite topping?“
-
3.2 Dialogue-Level Evaluation (Multi-Turn)
-
ACUTE-Eval: A “head-to-head” comparison where a human judge views two separate chat logs and decides which bot is more engaging or human-like.
-
Topic Metrics: * Topic Depth: How many consecutive turns the bot can stay on a single subject.
- Topic Breadth: The total range of different topics the bot can successfully navigate in one session.
4. Evaluation Frameworks
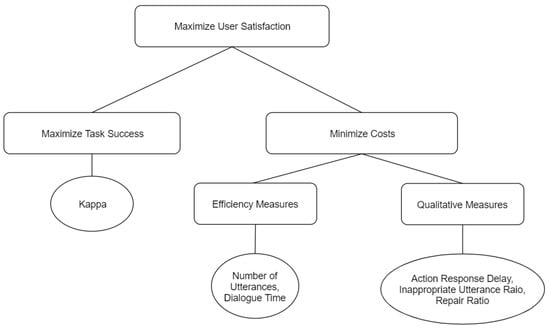
4.1 PARADISE (PARAdigm for Dialogue System Evaluation)
PARADISE assumes the ultimate goal is User Satisfaction (US). It uses multiple linear regression to show how different objective metrics (like length) predict subjective satisfaction.
- It balances the trade-off between Maximizing Task Success and Minimizing Costs (Efficiency + Qualitative measures like “Help” requests).
4.2 Quality of Experience (QoE)
QoE shifts focus from “Quality of Service” (technical stats) to the user’s perception. It categorizes “Influences”—such as the user’s previous experience with AI and the environmental context (e.g., using a smart speaker in a quiet home vs. a noisy car)—to predict overall acceptability.
4.3 Interaction Quality (IQ)
IQ uses Expert Raters to label dialogues turn-by-turn. Experts are often more reliable and consistent than casual users.
- Dynamic Adaptation: If the IQ score drops (indicating user frustration), a Dialogue Manager can automatically switch from a “Natural” strategy to an “Explicit Confirmation” strategy to prevent the user from hanging up.

5. The Best Way to Evaluate Dialogue Systems
There is no “Silver Bullet” metric; the choice depends on the system’s purpose.
-
Functional Systems: Use PARADISE. It calculates if the user achieved their goal and how much effort it cost them.
-
Social Systems: Use SSA and ACUTE-Eval. These prioritize engagement, interestingness, and the absence of “repetitiveness.”
-
Automated Trends: Researchers are moving toward Perplexity. This measures how “surprised” a model is by a sequence of words. Lower perplexity typically correlates with higher human ratings of “sensibleness.”
Summary Table: Metrics at a Glance
| Level | Metric Name | Best For… | Description |
|---|---|---|---|
| Speech | WER | ASR Accuracy | Measures insertions, deletions, and substitutions. |
| NLU | F1-Score | Intent Detection | A balance between Precision and Recall. |
| Turn | SSA | Chatbot Quality | Scores if a bot makes sense and isn’t too generic. |
| Dialogue | ACUTE-Eval | SOTA Comparisons | Humans choose the “winner” between two AI models. |
| Framework | PARADISE | User Satisfaction | A unified score for Task Success vs. Efficiency. |
| Intrinsic | Perplexity | Model Training | An automated stat used to predict human-like responses. |
Links:
Unit 1 Introducing Dialogue Systems
Unit 2 Rule-based Dialogue Systems
Unit 3 Statistical Data-driven Dialogue Systems
Unit 4 Evaluating Dialogue Systems
Unit 5 End-to-End Neural Dialogue Systems