View PDF
1. Neural Network Approaches to Dialogue Modeling
Traditionally, dialogue systems followed a “modular” or “pipelined” architecture where different components (NLU, Dialogue Manager, NLG) were built and optimized separately. Modern research has shifted almost entirely to End-to-End (E2E) approaches.
1.1 The Concept of Neural Dialogue
In neural dialogue, an input utterance is mapped directly to an output response using Deep Neural Networks (DNNs). This is called a Sequence-to-Sequence (Seq2Seq) mapping or transduction.
-
The Architecture: It replaces the complex chain of modules with a single unified model.
-
Input Handling: The model processes text (or transcriptions from speech recognition).
-
Output Handling: The model generates text (which can then be fed into a Text-to-Speech system).
1.2 Advantages over Modular Systems
-
Credit Assignment Problem: In pipelined systems, if a conversation fails, it is hard to know if the error was in the Speech Recognizer, the NLU, or the Manager. In E2E systems, the entire network is optimized together.
-
Joint Optimization: Optimizing modules together usually yields better results than optimizing them in isolation.
-
Domain Adaptation: Modular systems require re-tuning every module for a new domain (e.g., from flight booking to restaurant booking). E2E systems can often be retrained on new data with less manual handcrafting.
-
Reduced Handcrafting: E2E systems do not require extensive design of “state spaces” or “action spaces” required by Reinforcement Learning in modular systems.

2. A Neural Conversational Model
One of the most influential early E2E models was proposed by Vinyals and Le (2015). It treated conversation as a machine translation task, where the “source language” is the user’s query and the “target language” is the system’s response.
-
How it Works: It uses an RNN (Recurrent Neural Network) to read the input token by token. When the input ends, the hidden state of the RNN is stored as a Context Vector (or “thought vector”). This vector is then used by a decoder to generate the response token by token.
-
Results: The model was tested on IT helpdesk chats and movie subtitles. It was found to be very natural and could generalize to questions not found in the training set.
-
Limitations:
-
Blandness: It often produces short, uninteresting answers like “I don’t know” or “Okay.”
-
Inconsistency: It might say it is a lawyer in one turn and a doctor in the next because it doesn’t “remember” its persona.
-
3. Technology of Neural Dialogue
To understand how these systems work, we must look at the underlying “building blocks.”
3.1 Word Embeddings
Computers cannot process words; they process numbers.
-
One-Hot Encoding: A simple method where each word is a vector of 0s and a single 1. However, this is “sparse” (mostly zeros) and doesn’t show relationships between words (e.g., “king” and “queen” are just different indices).
-
Dense Embeddings (Word2Vec/BERT): These represent words as real-number vectors in a “semantic space.” Words with similar meanings are physically closer together in this space.
-
Vector Math: Embeddings allow for logic like:
vec("Berlin") - vec("Germany") + vec("France") = vec("Paris").
3.2 Recurrent Neural Networks (RNNs)
RNNs are designed for sequences. They have a “loop” that allows information to persist.
-
Memory: As the RNN reads “What are you doing…”, each word updates a “hidden state” that acts as the network’s memory.
-
The Vanishing Gradient Problem: Standard RNNs struggle with long sentences. By the time they reach the end of a long paragraph, they “forget” the beginning.
3.3 LSTMs and GRUs
To fix the memory problem, Long Short-Term Memory (LSTM) units were created.
-
Gates: LSTMs use “gates” to decide what information to keep, what to forget, and what to pass to the output.
-
GRU (Gated Recurrent Unit): A simpler, faster version of the LSTM that combines some of the gates.
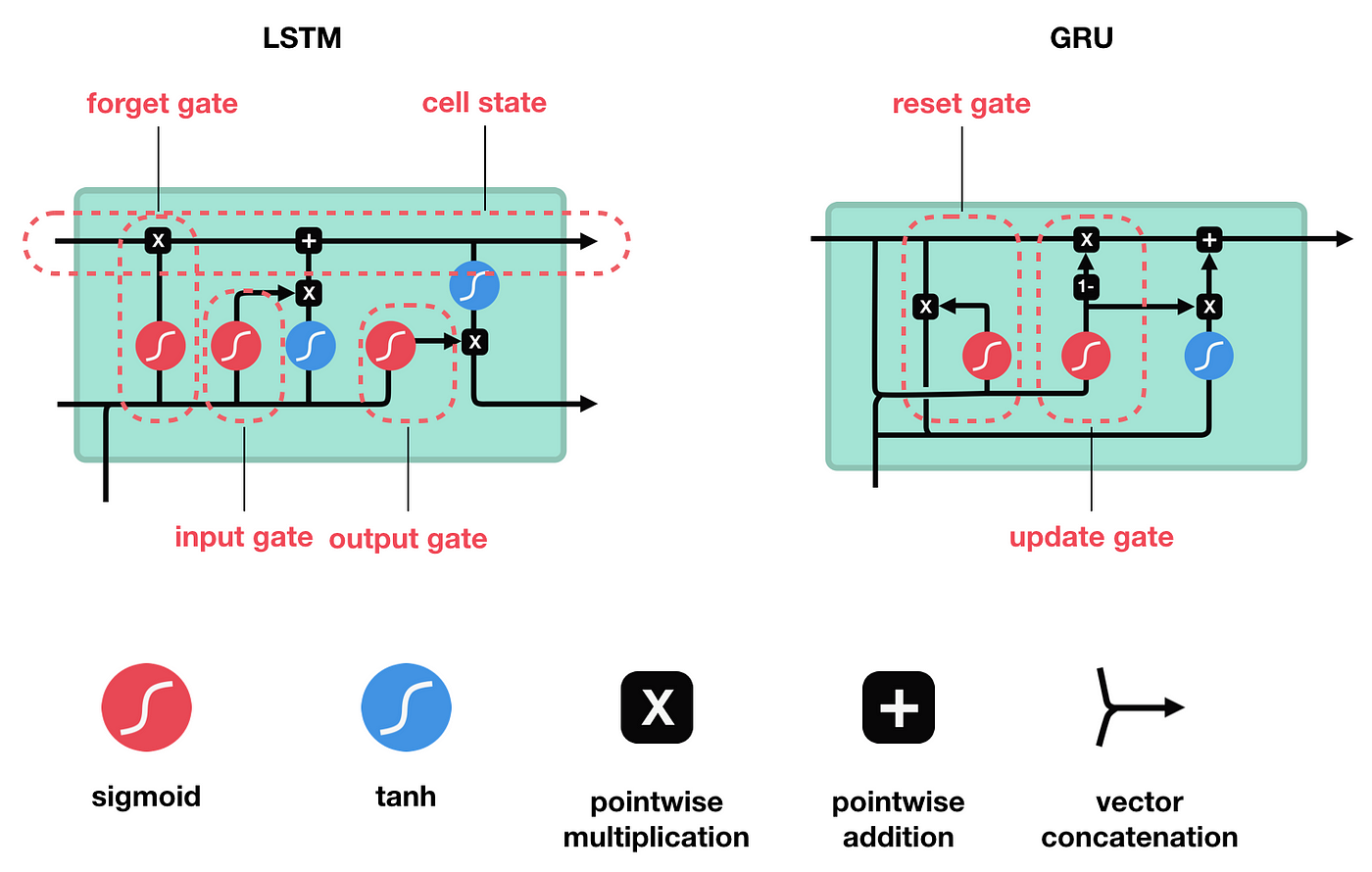
3.4 The Encoder-Decoder Architecture
This is the heart of Seq2Seq models.
-
Encoder: Processes the input sequence into a fixed-length Context Vector.
-
Decoder: Takes the context vector and generates the output sequence one word at a time (Autoregressive generation).
3.5 The Attention Mechanism and Transformers
-
Attention: Instead of squashing a whole sentence into one vector, the decoder is allowed to “look back” at specific parts of the input sentence that are relevant to the word it is currently generating.
-
Transformers: Introduced in 2017, this architecture replaced recurrence (loops) with “Self-Attention.” It allows the model to see the entire sentence at once, making it much faster and better at handling long-distance dependencies.
4. Retrieval-Based Response Generation
While Generative models create new text word-by-word, Retrieval-based models choose the best response from a pre-defined database.
-
Mechanism: The system encodes the user’s input into a vector and then calculates a “matching score” against thousands of candidate responses in a corpus.
-
Pros: Responses are always grammatically correct, safe, and can be highly interesting/detailed.
-
Cons: The system cannot handle topics it hasn’t seen before.
-
Ensemble Models: Modern systems often use both: they retrieve a few good responses and then use a generative model to “refine” them into a single, natural reply.
5. Task-Oriented Neural Dialogue Systems
Task-oriented systems (like booking a flight) are harder for neural networks than “chit-chat” because they require Accuracy and Logic.
-
Challenges:
-
They must interact with external databases or APIs.
-
They must fill “slots” (e.g., Departure City, Date, Time).
-
-
Neural Solutions:
-
Belief Tracking: Neural nets are used to track the “state” of the user’s goals (e.g., “The user definitely wants Italian food”).
-
Policy Networks: Deciding whether to ask a question, provide an answer, or book the table.
-
Hybrid Approaches: Using an RNN to map input to a database query, then inserting the database results into a sentence template.
-
6. Open-Domain Neural Dialogue Systems (State-of-the-Art)
These are systems designed for general conversation (Socialbots).
6.1 Alexa Prize 2020
Teams from universities compete to build bots that can chat for 20 minutes.
- Advances: Use of large-scale Transformers, common-sense reasoning, and sentiment classifiers to make the bot more empathetic.
6.2 Google’s Meena
-
Scale: 2.6 billion parameters.
-
Architecture: Evolved Transformer.
-
Evaluation: Google introduced the SSA (Sensibleness and Specificity Average) metric. Meena was found to be significantly more “human-like” than older bots like Mitsuku or Cleverbot.
6.3 Facebook’s BlenderBot
BlenderBot focuses on “blending” three skills:
-
Personality: Being consistent.
-
Empathy: Understanding user emotions.
-
Knowledge: Providing facts from Wikipedia.
- Retrieve-and-Refine: It retrieves a fact and then “blends” it into a generative response.
6.4 OpenAI’s GPT-3
-
Scale: 175 billion parameters.
-
Few-Shot Learning: It can learn to perform a task (like translation or dialogue) by being shown just 2 or 3 examples in the prompt.
-
Limitations: It can lose coherence over very long conversations and lacks a “memory” of who the user is unless specifically programmed to track state.
7. Some Issues and Current Solutions
7.1 The Generic Response Problem
Neural models tend to prefer “safe,” high-probability responses like “I don’t know” or “I’m not sure.”
- Solution: Maximum Mutual Information (MMI). Instead of choosing the most likely response, the model chooses the response that is most specific to the input.
7.2 Semantic Inconsistency
The bot might contradict itself (e.g., saying “I don’t have a job” then “I am a lawyer”).
- Solution: Persona-based models. The model is given a “persona vector” (a set of facts like “I live in London,” “I like cats”) that stays constant throughout the conversation.
7.3 Affect and Emotion
Standard bots sound like robots.
- Solution: Emotional Chatting Machine (ECM). The model is conditioned on an emotion category (Happy, Sad, Angry) so that its wording changes based on the desired mood.
8. Datasets, Competitions, and Challenges
Neural dialogue requires massive amounts of data.
8.1 Key Datasets
-
MultiWOZ: 10,000 dialogues for task-oriented multi-domain tasks.
-
Ubuntu Dialog Corpus: 1 million conversations about technical support.
-
Twitter/Reddit: Massive but “noisy” datasets for open-domain chit-chat.
-
Persona-Chat: Dialogues where speakers adopt specific characters.
8.2 Key Competitions
-
DSTC (Dialog System Technology Challenge): The primary research competition focusing on state tracking and E2E learning.
-
Alexa Prize: Focuses on socialbots and conversational duration.
-
Dialogue Breakdown Detection Challenge: Focuses on identifying when the bot has made a mistake so it can recover.
Links:
Unit 1 Introducing Dialogue Systems
Unit 2 Rule-based Dialogue Systems
Unit 3 Statistical Data-driven Dialogue Systems
Unit 4 Evaluating Dialogue Systems
Unit 5 End-to-End Neural Dialogue Systems